Research Data Management
What constitutes research data?
Material or information necessary to come to your conclusion
Types of research data
- By origin
- Observational
- Experimental
- Simulation
- Derived/Compiled
- Reference
- By form
- Textual (field notes, transcripts)
- Numeric/Tabular (spreadsheets, databases)
- Geospatial (GIS, satellite imagery)
- Audio/Video (interviews, sensor feeds)
- Images (scans, microscopy)
- Code/Software (scripts, models)
What counts as data in your field?
The data lifecycle
Stages of research data
- Planning
- Collection
- Processing and cleaning
- Analysis
- Sharing and publication
- Preservation and reuse
Data degrades over time
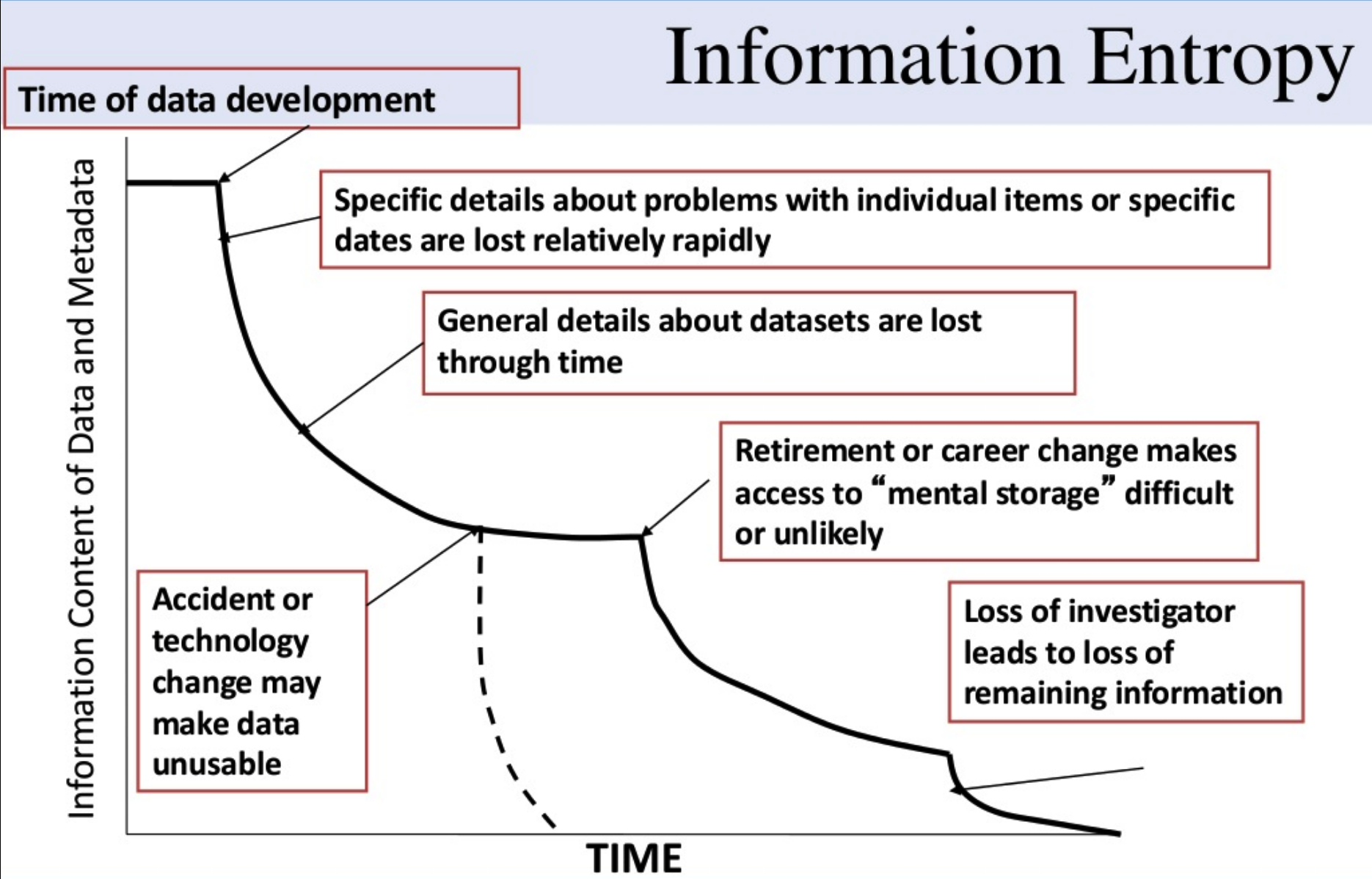
Michener et al. (1997) doi:10.1890/1051-0761(1997)007[0330:NMFTES]2.0.CO;2
Why manage and share data?
The case for sharing
- Others can check and reproduce your work
- Someone else can build on what you collected
- Your data becomes citable, so you get credit
- Funders and journals now require it
Data disappears
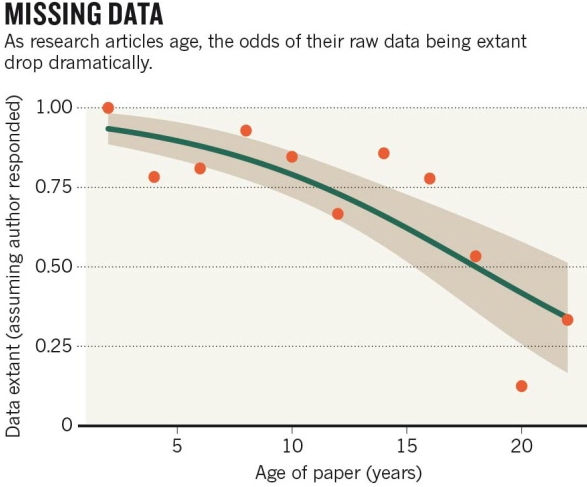
Vines et al. (2014) Current Biology. doi:10.1016/j.cub.2013.11.014
Funder mandates
- NIH (January 2023)
- Data Management & Sharing Policy: plan required for all proposals generating scientific data
- NSF (May 2024)
- PAPPG 24-1: data supporting publications shared at time of publication
- OSTP (August 2022)
- Nelson Memo: all federal agencies updating public access policies
- DOE, USDA, NEH...
- Agency-specific mandates continue to expand
If your research is federally funded, data sharing is required.
The FAIR principles
You'll see this acronym everywhere in funder requirements.
FAIR
- Findable
- Give it a DOI and describe it so people can search for it
- Accessible
- Put it somewhere people can actually download it
- Interoperable
- Use formats and terms others in your field will recognize
- Reusable
- Say what the data is and what others are allowed to do with it
Wilkinson et al. (2016) Scientific Data 3:160018
FAIR in practice
- Restricted or sensitive data can still be FAIR
- FAIR applies to data and metadata
- Partial compliance still counts. Do what you can.
- Funders and journals now expect it
Data management plans
What goes in a DMP?
- Data types and formats expected
- Standards and metadata
- Data storage and backup
- Access policies and sharing timeline
- Privacy, security, and ethics
- Preservation and repository selection
Typically 2 pages. Written at proposal stage, updated during the project.
NIH vs. NSF
- NIH DMS Plan
- Applies to all scientific data
- Must name a repository
- Budget for data management allowed
- Reviewed by program staff
- NSF DMSP
- 2-page supplementary document
- Discipline-specific expectations
- Data shared at publication
- Reviewed by peers
DMP tools
- DMPTool (dmptool.org)
- Templates aligned to funder requirements
- DMPOnline (dmponline.dcc.ac.uk)
- UK/international equivalent
- Funder templates
- NIH, NSF, NEH each provide specific guidance
Best practices
File naming
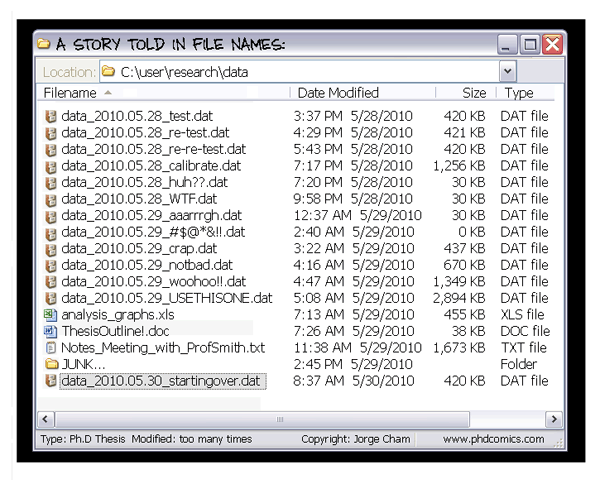
Jorge Cham, PHD Comics
File naming conventions
- Use consistent, descriptive names
- Include dates in YYYY-MM-DD format
- Avoid spaces and special characters
- Include version numbers (v01, v02) or use version control
- Agree on conventions within your project team
Example:
survey_responses_2025-01-15_v02_cleaned.csvTidy data structure
- Each variable in its own column
- Each observation in its own row
- Each type of observational unit in its own table
- Human-readable column headers
- Related tables linked by key/ID columns
Wickham, H. (2014) "Tidy Data." Journal of Statistical Software 59(10)
Documentation
Every dataset needs a README and a data dictionary.
- README
- Project context, file descriptions, collection methods
- Data dictionary
- Variable names, units, allowed values, missing data codes
- Metadata standards
- Dublin Core, DDI, Darwin Core, or discipline-specific
Version control
- Git/GitHub: track changes, collaborate, maintain history
- For code and data (small datasets, scripts, notebooks)
- DVC (Data Version Control): Git-like tracking for large data files
- At minimum: consistent file naming with version numbers
- Never overwrite raw data. Keep originals untouched.
Sharing and preserving data
Where to deposit data
- Domain-specific repositories
- ICPSR (social science), GenBank (genomics), PANGAEA (earth science)
- Generalist repositories
- Zenodo, Dryad, Figshare, Dataverse, OSF
- Institutional repositories
- CUNY Academic Works (academicworks.cuny.edu)
re3data.org — Registry of Research Data Repositories
Data citation
- Datasets get DOIs via DataCite
- Citation format: Creator (Year). Title. Repository. DOI
- Data citations appear in reference lists alongside papers
- Proper citation gives credit to data creators
- ORCID links researchers to their datasets
Preservation formats
- Prefer
- Open, non-proprietary formats
- CSV over Excel
- TIFF/PNG over PSD
- Plain text, PDF/A, XML, JSON
- Uncompressed or lossless
- Avoid
- Proprietary binary formats
- Software-dependent formats
- Formats without open specs
- Lossy compression
- Encryption without documented keys
Storage media have lifespans

CrashPlan / Code 42 Software
Key takeaways
- Write your DMP at the proposal stage
- Document everything. "Future you is your first user."
- Use open formats and standards
- "Think FAIR when deciding how to share"
- Deposit in a repository and get a DOI
- CUNY Academic Works: academicworks.cuny.edu
Resources
- DMPTool: dmptool.org
- re3data.org: Registry of Research Data Repositories
- FAIR Principles: go-fair.org
- DataCite: datacite.org
- Library of Congress Recommended Formats: loc.gov/preservation/resources/rfs/